Trocco's product architecture is developed to suit the practical needs of professional data engineers. Designed to take into account not only transfer speeds and connector count, but also reliability, scalability and security.
In today’s competitive landscape, data mining has become a cornerstone for businesses seeking actionable insights from their data. However, effective data mining requires clean, consistent, and unified data that is achieved through data integration. This guide explores what data integration in data mining is, its importance, methods, tools, and best practices for businesses.
What is Data Integration in Data Mining?
Data integration in data mining is the process of merging data from multiple, often disparate, sources into a unified view. This ensures consistency and usability, enabling businesses to derive accurate insights during the mining process.
For instance, a retail company might integrate data from its point-of-sale (POS) systems, customer relationship management (CRM) software, and online store to analyze buying patterns. Without data integration, discrepancies between these systems could lead to flawed analysis and missed opportunities.
Key Steps in Data Integration
Data Extraction: Identifying and retrieving data from multiple sources (e.g., databases, cloud platforms, APIs).
Data Transformation: Standardizing and cleansing the data to ensure it aligns with a unified format.
Data Loading: Storing the transformed data in a centralized repository, such as a data warehouse or data lake.
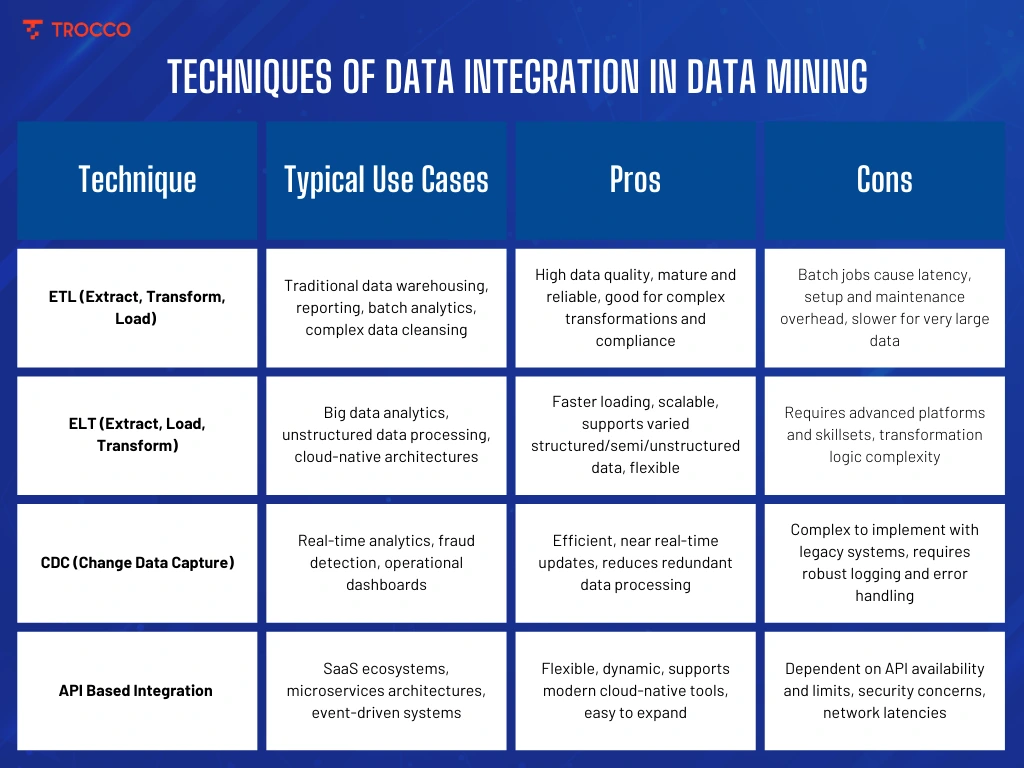
The primary techniques for data integration include:
Extract, Transform, Load (ETL): ETL is the classic data integration approach laid upon three main pillars, namely extract, transform, and load; whereby, extract is to pull data from various sources, be it databases, files, or cloud solutions, transform is to clean raw data, and standardizes it by managing inconsistencies, reverting duplications, and changing data formats for proper alignment across all datasets, and finally, transform is to load the transformed data into a target data repository, such as a data warehouse or a data lake, providing a single reliable source of "truth" for the mining algorithms.
Strengths: Mature, effective, completely configurable. They deliver very high-quality and precise datasets amenable to in-depth logical analyses or trend analyses of a historical nature.
Limitations: Typically batch-wise in nature and tend to develop latency, making them inappropriate for real-time analysis.
Extract, Load, Transform (ELT): ELT reverses the order of the last two operations in ETL. In the extract phase, the data is taken from sources. The load phase includes the immediate loading of raw data, most often to cloud storage or data lakes. In the transform phase, data processing takes place directly within the data platform, typically leveraging powerful cloud resources.
Strengths: Highly scalable, accommodates big data and complex transformations post-loading. Best suited for cloud architectures where computational resources are plentiful.
Limitations: Advanced tools or skillsets may be needed, and can create a complex management environment without specialized solutions.
Change Data Capture (CDC): Change Data Capture continuously monitors and captures the changes of data (insert, update, and delete) from the source systems and applies them to target data repositories in near real-time.
Strengths: Supplies up-to-date, highly dynamic datasets. A major prerequisite for cases where the freshness of data and speed of analysis are paramount, such as fraud detection and real-time analytics.
Limitations: Setting up can be quite technically complicated when legacy applications and logging requirements are involved. Besides, maintaining data integrity during frequent updates is complex.
API-Based Integration: In this technique, APIs are used to connect several data sources for a real-time or on-demand flow of data.
Strengths: It allows a high degree of flexibility and interoperability among heterogeneous modern SaaS platforms, microservices, or mobile applications. Best for environments in need of a frequent data sync and quick scalability.
Limitations: Demands a reliable API endpoint and robust security. Restrictions or rate limits on API access could affect its utilization.
Try TROCCO's Data Integration Tool, which seamlessly automates data collection, transformation, and integration from multiple sources into a unified pipeline for faster, cleaner insights, resulting in robust data mining.
Streamlining Data Integration with TROCCO
TROCCO, a fully managed modern data platform, simplifies data integration with powerful automation tools and an intuitive interface. Here's how it optimizes the integration process:
100+ Connectors: TROCCO supports seamless integration across various databases, SaaS platforms, and cloud environments.
Automated Workflows: Streamlines complex processes with job scheduling and dependency management.
Data Transformation Tools: Offers advanced scripting capabilities (e.g., Python, Ruby) and supports dbt Core integration.
Metadata Management: Ensures data traceability and governance through a robust catalog.
Best Practices for Data Integration in Data Mining
Define Clear Objectives: Understand what you want to achieve with data integration.
Prioritize Data Quality: Regularly validate and cleanse data to maintain its accuracy.
Leverage Automation: Use platforms like TROCCO to automate repetitive tasks.
Monitor Performance: Continuously track integration processes to ensure efficiency.
Enable Metadata Management: Organize and document your data to enhance traceability and governance.
Real World Examples
Retail and E-Commerce: Analyze customer behavior, optimize inventory, and enhance personalization.
Finance: Detect fraud, predict market trends, and improve compliance.
Healthcare: Integrate patient data for better diagnostics and treatment planning.
Marketing: Measure campaign performance by integrating data from multiple channels.
What is data integration in data mining? Data integration in data mining refers to the process of combining data from different sources into a unified dataset before analysis. It ensures consistency, removes duplicates, and aligns formats to support accurate pattern discovery. In data mining, integrated data helps uncover meaningful trends by providing a complete and reliable foundation for algorithms. Without proper integration, results can be biased or incomplete, especially when data comes from multiple databases, APIs, or platforms.
What are the data integration techniques? Common data integration techniques include:
Manual Integration – Hand-coded data merging (used in small setups)
ELT (Extract, Load, Transform) – Used in cloud-native environments
Data Virtualization – Real-time unified access without physical consolidation
Middleware-Based Integration – Uses APIs or connectors to sync systems
Data Replication – Copies data across environments for consistency Each technique serves different use cases based on latency, complexity, and infrastructure.
What are the top 5 data integration patterns? The top 5 data integration patterns are:
ETL Pattern – Standard batch processing workflow
Streaming Pattern – Real-time integration using tools like Kafka
API-Based Integration – Connects systems via REST or GraphQL
Data Virtualization – Accesses data without moving it
Change Data Capture (CDC) – Tracks and syncs only updated data These patterns address different needs for latency, data freshness, and scalability in modern data architectures.
What is an example of data integration? A common example of data integration is syncing customer data from an e-commerce platform, email marketing tool, and CRM into a single data warehouse. For instance, a business might use TROCCO to pull order data from Shopify, email engagement from Klaviyo, and customer profiles from Salesforce, then merge it into BigQuery for unified analysis. This enables personalized marketing, better forecasting, and data-driven decisions across teams.
Conclusion
What is data integration in data mining? It’s the foundation of any successful data mining initiative. By combining data from various sources, organizations can unlock insights, streamline processes, and drive strategic growth.
Simplify your data integration and mining workflows with TROCCO's powerful platform. From automation to advanced transformation tools, TROCCO empowers businesses to make data-driven decisions effortlessly. Get a trial plan now and connect with us to know more.
Sign up for weekly updates
Get all the latest blogs delivered to your inbox
Thank you! Your submission has been received!
Oops! Something went wrong while submitting the form.







.webp)
.webp)







